Sandman Slim (Sandman Slim, #1)

|
Review:Not horrible. The language is an impossible high-noirish pastiche. Fun. |
|
|
Review:Not horrible. The language is an impossible high-noirish pastiche. Fun. |
There is one area where Qt and Python (and in consequence PyQt) have major disagreements. That area is memory management.
While Qt has its own mechanisms to handle object allocation and disposal (the hierarchical QObject trees, smart pointers, etc.), PyQt runs on Python, so it has garbage collection.
Let's consider a simple example:
from PyQt4 import QtCore def finished(): print "The process is done!" # Quit the app QtCore.QCoreApplication.instance().quit() def launch_process(): # Do something asynchronously proc = QtCore.QProcess() proc.start("/bin/sleep 3") # After it finishes, call finished proc.finished.connect(finished) def main(): app = QtCore.QCoreApplication([]) # Launch the process launch_process() app.exec_() main()
If you run this, this is what will happen:
QProcess: Destroyed while process is still running. The process is done!
Plus, the script never ends. Fun! The problem is that proc is being deleted at the end of launch_process because there are no more references to it.
Here is a better way to do it:
from PyQt4 import QtCore processes = set([]) def finished(): print "The process is done!" # Quit the app QtCore.QCoreApplication.instance().quit() def launch_process(): # Do something asynchronously proc = QtCore.QProcess() processes.add(proc) proc.start("/bin/sleep 3") # After it finishes, call finished proc.finished.connect(finished) def main(): app = QtCore.QCoreApplication([]) # Launch the process launch_process() app.exec_() main()
Here, we add a global processes set and add proc there so we always keep a reference to it. Now, the program works as intended. However, it still has an issue: we are leaking QProcess objects.
While in this case the leak is very short-lived, since we are ending the program right after the process ends, in a real program this is not a good idea.
So, we would need to add a way to remove proc from processes in finished. This is not as easy as it may seem. Here is an idea that will not work as you expect:
def launch_process(): # Do something asynchronously proc = QtCore.QProcess() processes.add(proc) proc.start("/bin/sleep 3") # Remove the process from the global set when done proc.finished.connect(lambda: processes.remove(proc)) # After it finishes, call finished proc.finished.connect(finished)
In this version, we will still leak proc, even though processes is empty! Why? Because we are keeping a reference to proc in the lambda!
I don't really have a good answer for that that doesn't involve turning everything into members of a QObject and using sender to figure out what process is ending, or using QSignalMapper. That version is left as an exercise.
Again: spanish only!
Después de mi post de ayer acerca de la letra de "Paisano de Hurlingham" recibí un aluvión de correcciones y explicaciones, que enumero a continuación.
Es una referencia a Opalinas Hurlingham, una fábrica abierta en 1948, y abandonada desde 1994. Hay una interesante colección de fotos de su interior en flickr
La empresa fué a la quiebra principalmente por un juicio pionero sobre daño ambiental: envenenaba las napas de la zona con arsénico.
Es el ramal Retiro/Pilar del ferrocarril San Martín, que efectivamente pasa por Hurlingham. Mea culpa.
Las abejas son trabajadoras. Ombú es la marca más conocida de ropa de trabajo en Argentina. Habla tal vez mal de mí que no se me ocurriera.
Mi mamá hacía explotar sapos forzándolos a fumar, cuando era chica. No he oído otra referencia a sapos explosivos.
Sigue siendo un misterio el porqué el sapo explota los domingos a las 10.
Jerga zonal acerca de ser un malandra.
Me acercan rock checo, aunque no eslovaco.
Desde ya muchas gracias por sus aportes!
Sorry, spanish only post. But you can listen to the song here

Si tuviera 5 blogs y la energía para postear en todos, el cuarto sería "analizando demasiado la letra de canciones". En homenaje a ese blog que nunca va a existir, este sería el primer post: Paisano de Hurlingham, de Divididos (probablemente mi banda favorita).
Primero, la letra completa:
Al parecer hay un cierto consenso (entre las tres personas a quienes les pregunté), de que esta canción es la descripción de un viaje en tren.
Las letras de Divididos no se caracterizan por ser interpretables linealmente, De hecho, sospecho que la mayoría son simplemente una serie de palabras una después de la otra porque "suenan bien juntas".
El primer verso "Paisano de Hurlingham" es el título mismo de la canción, y, supongo, el protagonista de esta mínima odisea suburbana. "poda neblina" es interesante. No encuentro (gracias google) ninguna referencia a esa frase fuera de esta canción. Es posible que nadie jamás haya dicho "poda neblina" hasta que Mollo cantó esa estrofa.
Para que se hagan una idea de lo raro que es eso, hay dos referencias independientes a "navaja desierta", que son dos palabras al azar sacadas del diccionario. ¿Entonces, qué es "poda neblina"? Bueno, si es muy temprano, hay neblina, y el paisano la atraviesa, la corta, la poda. Así que, tirando de los pelos (que lo vamos a hacer bastante), podemos suponer que nos ubica temporalmente en una madrugada neblinosa.
Más obvio es "moneda o botón". Habla de hacer trampa, de pasar un botón donde debería haber una moneda. No se puede hacer eso con el cajero, ni con un vendedor, pero sí se puede en la limosna del "ciego bilingüe".
"paso morales" es obvia. Es la calle Paso Morales, en Villa Tesei. De hecho esa calle corta la vía del tren que viene de Chacarita, lo que confirma que hablamos de un viaje por las vías.
Es difícil justificar "sin la opalina". De hecho, no lo voy a intentar. "de Retiro a Pilar / busca el chancho al chabón" es tal vez la línea más obvia: es un guarda de tren que busca a un pasajero que no paga, y lo persigue desde Retiro a Pilar. El problema con esa obviedad es que:
El tren que hace Retiro/Pilar no pasa por Hurlingham
El tren que corta Paso Morales sale de Chacarita (y sí pasa por Hurlingham).
¿Es tal vez que "De Chacarita a Hurlingham" es imposible desde un punto de vista de métrica? Sería comprensible si así fuera.
"Sapo explota en San Martín / los domingos a las diez" es oscura. Además de que ninguna de las líneas de ferrocarril mencionadas pasa por San Martín. ¡Pero el recorrido Retiro/Pilar es de la línea San Martín! Si bien no logramos esclarecer qué sapo explota, porqué ni dónde, sí sabemos el cuándo. Esto fortalece la hipótesis de que el paisano por algún motivo está yendo a Pilar.
También es sanmartiniana la referencia al "sable recto en la estación", por contraposición al famoso sable corvo del General. Que nunca jamás tuvo el grado de Mayor (ascendió de capitán a general), lo que complica encasillar "berretín de mayor".
"Canilla en el andén / gotea noticias / te grita el titular / mentiras sin picar" es directa. Un canillita, un canilla, es un vendedor de diarios. Las canillas gotean, los canillitas gotean noticias. Gritan los titulares (aunque creo que ningún canillita grita los títulos desde 1947 o algo así). Mentiras sin picar, porque el papel no está picado, todavía, porque es un diario de hoy.
Y llegamos a la estrofa final, "Abejas con ombu / viajando en el panal / va la timba en el furgón." Me resisto a dar una interpretación, mas allá de que las abejas en el panal van apretadas, y que ombú es una marca de papel para armar cigarrillos, que seguramente la gente de la banda ha usado en abundancia para drogarse, un ingrediente que sospecho importante en la escritura de sus letras.
¿Qué conclusión podemos sacar de este análisis? Bueno, yo, personalmente, preferiría no entender lo que dicen, que Divididos fuera una banda de rock eslovaco, y poder sentir la patada en la frente que es esta canción sin tratar de entender qué carajo es "sapo explota en san martín". Pero eso es un problema mío.
UPDATE: Algunas aclaraciones, datos extras, y un tema de rock checo, aquí
am very distracted when I walk down the street. Or rather, I am paying a lot of attention, but it's spread over a whole lot of different things.

Her name is Faith Popcorn. Seen on Mar del Plata.
My favourite, since I am a compulsive reader, is reading street signs. There is always something off about signs in a foreign country. They are either about things other countries don't care about, or are written in a completely different style.

Fixed hair braiding prices in Bahamas
And sometimes you run into things you just have never seen before. Those things can be found anywhere, and can be anything, since ... well, you have never seen them before.

And now, a hydrant wearing a sweater in Budapest.
It doesn't have to be something really strange, it may just be something you have not seen before by chance.

Street sweepers get OCD too. Seen on San Isidro.
Or maybe you just figure something out right there and then.

So that's why sugar cubes are better. Seen in Budapest.
Or ... you don't know what to say.

Seen at Tigre. I have no idea.
Or things you don't have where you come from.

Blimp! Seen in London.
Or they are just so polite to ask.

Or you don't understand at first.
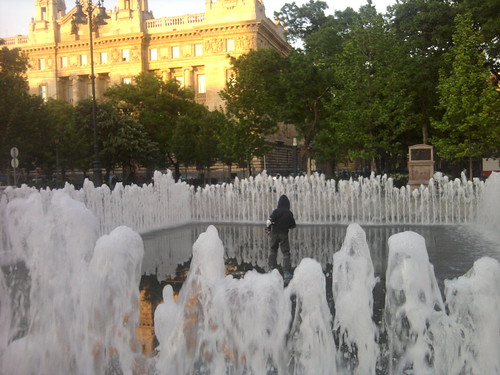
How did that kid get there?
And then you do.

It's a trick fountain! Seen in Budapest.
Or maybe it's something you see every day, out of context.

A typical argentinian milanesa sandwich. Bought on the street in Budapest.

A DIA% supermarket, like the one near my home. In Istanbul.
And sometimes it's something you never suspected even existed, or how it could exist.

This is a chapter in a turkish book. It takes place at my wedding.
Or out of context.

Seen around the corner of my house.
Or alien.

Hotel towel, seen in Orlando, Florida.
Or

Yes, I did get a haircut. Seen in London.
Or

Ferry in Istanbul
Or

True TV Remote seen in a hotel in Avenida de Mayo, Buenos Aires, in 2004.
this, except for that TV remote, is just a small sample of what I have seen in the last 12 months. These have been a really cool 12 months.