Urssus: July 28th late at night - Released 0.2.0 and it's outdated already (with screenshots)
Yes, I released 0.2.0, and announced it on PyPI, Freshmeat and kde-apps.org, we'll see what happens.
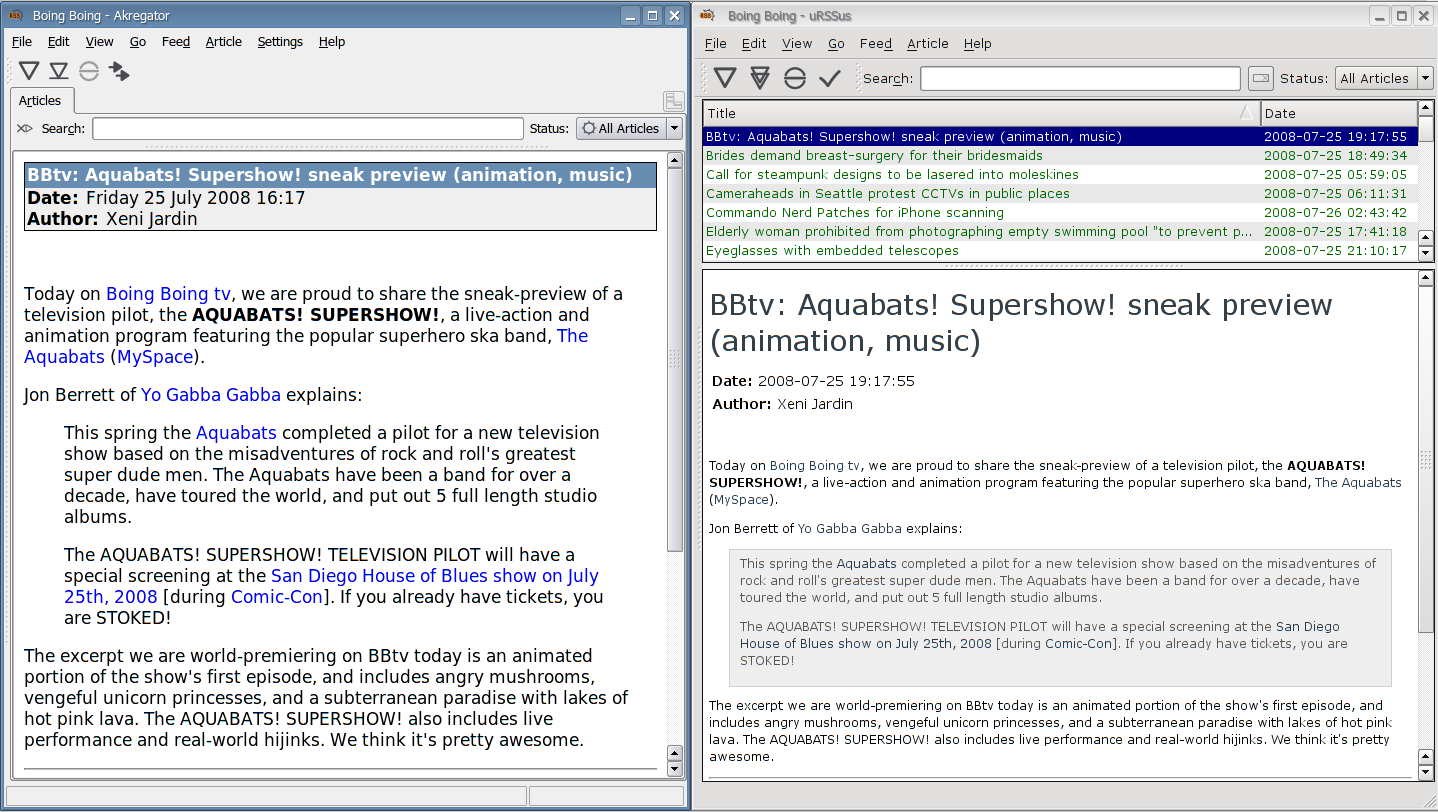
But why is it outdated? Because I am doing nicer UI work, already.
The search widget is now a bottom-locked toolbar, which is much cleaner.
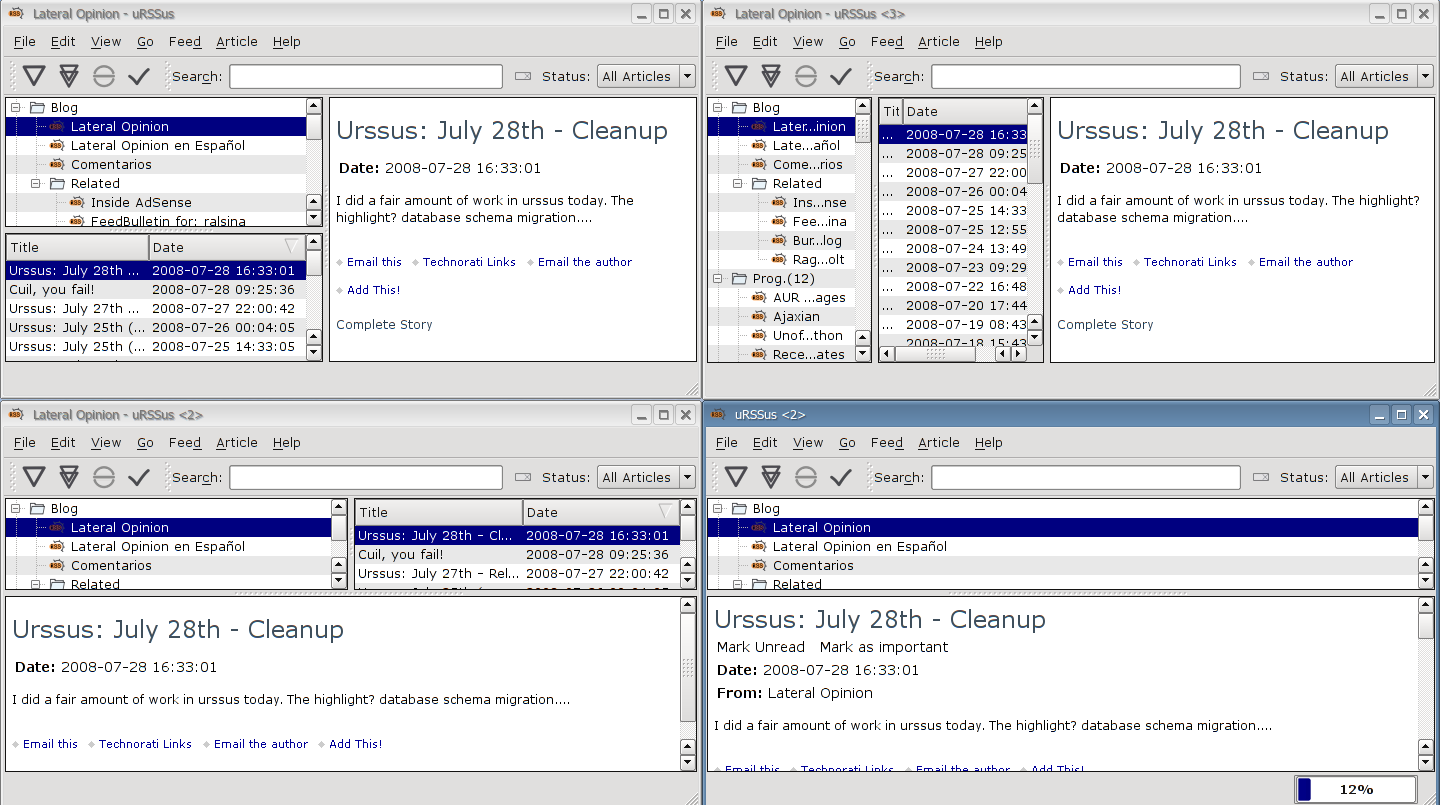
There are now 3 window layouts (normal, widescreen and combined) and each has a "long feed list" and a "short feed list" variant.
Here is widescreen-long:
And here are widescreen-short, widescreen-long, normal-short, and combined-short, all scrunched in a single screen (yes, you can run multiple urssus (urssuses? urssi?):