Posts about programming (old posts, page 37)
Urssus: import from google reader
It was rather easy because I didn't do the hard part (thanks authors of pyrfeed!)and now uRSSus has a simple "import my subscriptions from Google Reader" action.
All I can say is "it works for me" and "Google sure strips data from the feeds!".
It will import your tags as top-level folders (merged with whatever you already had).
Should be smart enough not to duplicate feeds or folders.
If a feed is in more than one folder, it will show in the first listed by google (no idea what the order is).
Urssus: August 2nd - going small
Mostly, I spent my two hours today refactoring. But also, testing how uRSSus looks on a small screen. Take a look:
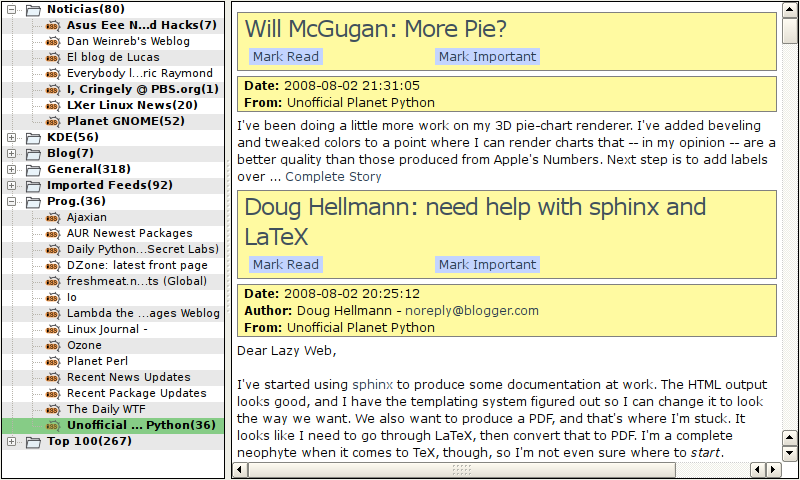
This is urssus in the configuration I liked best on my 7", 800x480 eeePC's screen.
As you can see, a more compact template for the combined view is a must, and I will implement a compact template. Or maybe just make a configuration option where you choose what template the combined view uses, to avoid the multiplication of "modes" that are the exact same thing under the hood.
Using combined view with all bars hidden and fullscreen makes for a rather large reading area, which is nice.
The performance in that limited computer was good... until the memory usage balloons. While uRSSus is not too CPU hungry, it's pretty memory intensive. There are obvious ways to improve that, of course, and I am exploring them.
BTW, I have not measured this in a while: 1957 lines of code. And still quite fun!
Urssus: no release today
I had planned to release a new version today, but there are too many untested features. A list:
Feed reordering via drag and drop
Unique app. The second uRSSus just makesthe first one operate.
Lots of refactoring to cleanup View/Model related things.
Since it's a lot of code, it will need a day or two of testing. Or a week.
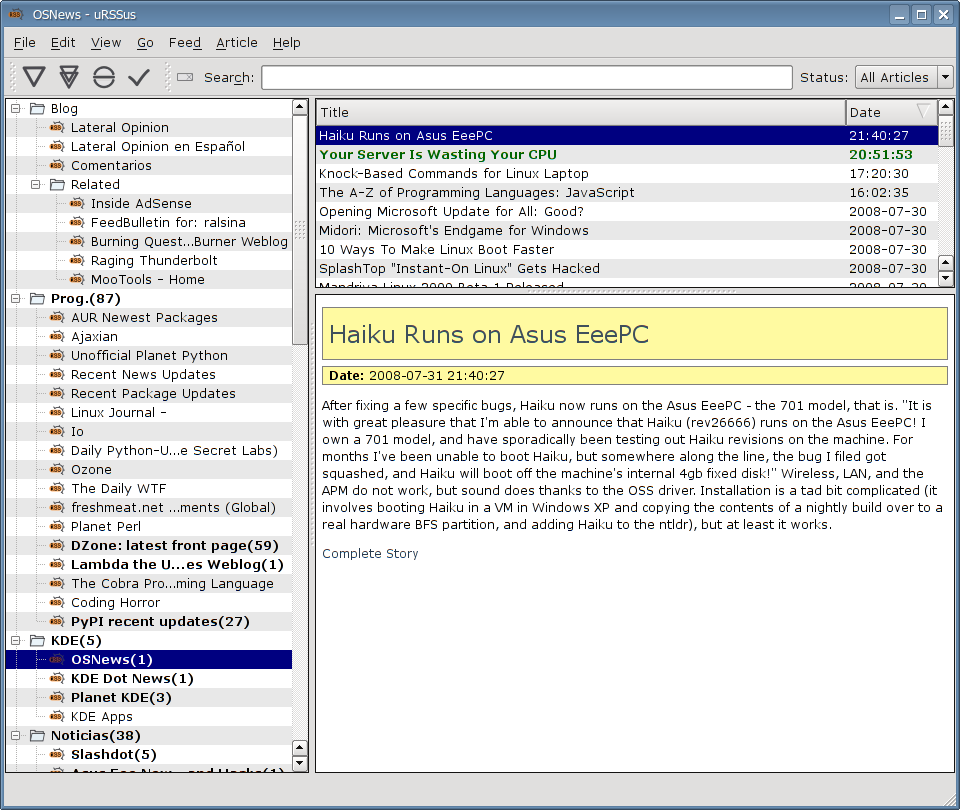
Urssus: July 31st - Many small things (with not-too-cool screenshot)
Helped by the testing by vgarvardt, many issues and possible features have been fixed or implemented in the last two days. Here's an incomplete list:
Implemented (and later fixed) proper close-to-tray
Marking a folder as read marks all its children
The reset filter button works like Akregator's
The tray changes its icon when there are unread items (and shows a count in the tooltip). Icon work needed, though.
Double click on a post opens in external browser
Default refresh period is configurable (no UI yet)
The feed tooltip shows unread count
Window size and position is memorized
Position of the splitters is memorized
Toolbar titles are now reasonable (never tried to right-click a Qt toolbar before)
Better templates for feed and post layouts
Unread items/feeds are now shown bold
The about window has the right title and icon, and doesn't appear in the taskbar.
There is almost certainly going to be a release tomorrow.
And here's a picture: