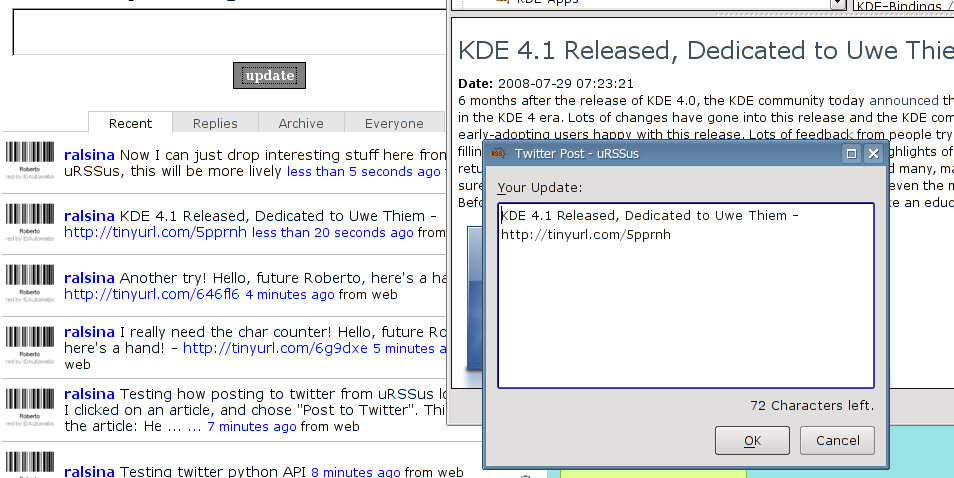
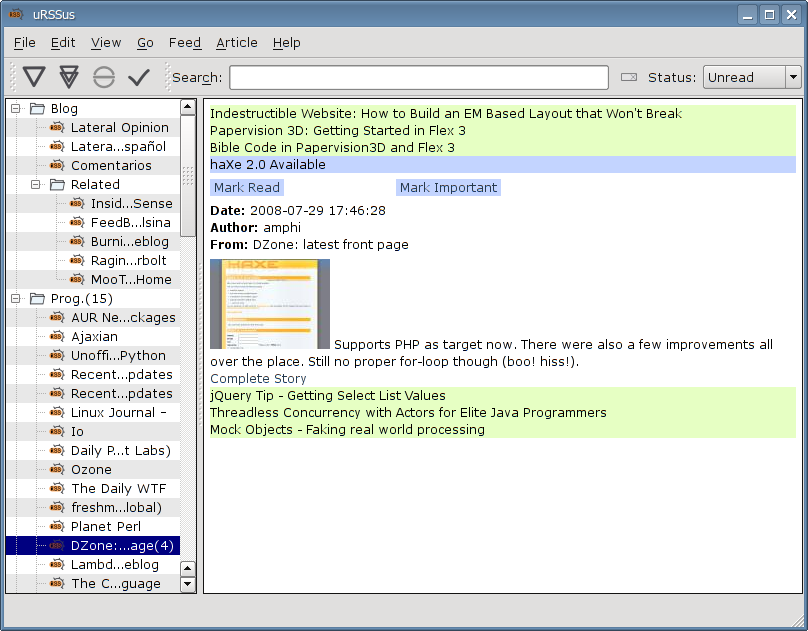
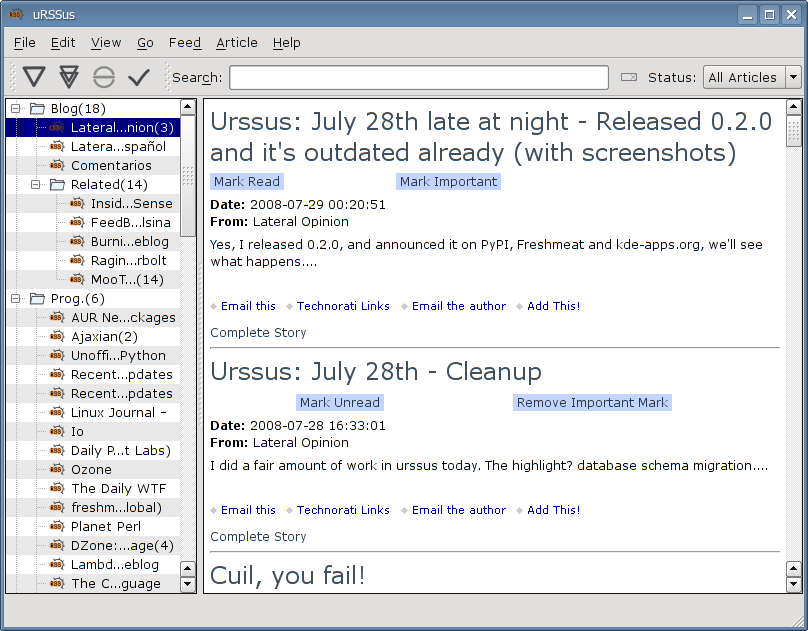
Urssus: July 30th (way too late). Now with users!
At least three people have tried urssus (including me ;-) and over 80 have downloaded it. The two that told me anything say it's a nice app.
I hope it keeps improving.
Right now, it has about a dozen less bugs (or more features) thanks to the issue reports by vgarvardt!