Reading DZone I ran into an interesting post titled Screw all GUI builders which advocates dropping all GUI builders and instead coding your UI by hand.
I always advocate using Qt Designer instead of coding by hand, so I wanted to see, even it's talking about Java, I thought, "why don't I feel that way"?
My conclusion? I don't see it because in PyQt we are just lucky because our tools don't suck quite as much.
It gives several arguments:
To that, my reaction was yes, indeed I don't care, as long as it works, which it has 99.99% of the time. When it didn't, I did understand the generated code, though.
The reason for this will be more obvious once you see the code in both cases, I think.
Hmmm... I really don't know what this means in context, but that's just my java ignorance. OTOH, yes, one class per window, but almost never thousands of lines of code.
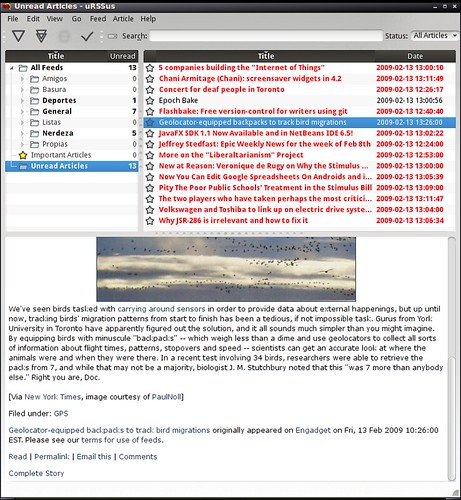
For example, the UI for uRSSus main window is quite complex, and it is only 530 lines of code. Here's how it looks, so you see it's not a trivial window:
* Most GUI builders don't want you to modify the generated code. And if you do, they either break or rewrite your code.
Indeed Designer's code is not meant to be modified. That's what inheritance is there for. Overload whatever you want changed. Maybe this is easier in PyQt because Python is more dynamic than Java? Not sure.
Just not true for Designer. I can see how that would suck, though.
The generated code is far from being optimal. It's not resize-friendly, not dynamic enough, it has many hard-coded values, refactoring is most likely impossible, because builder would not allow that.
Designer does generate resize-friendly dialogs if you use it correctly. The hard-coded values are runtime-editable, refactoring is pretty simple (take whatever you want, create a widget with it?)
And since I wanted to compare apples to apples...
Here is his dialog, done via PyQt and Designer:
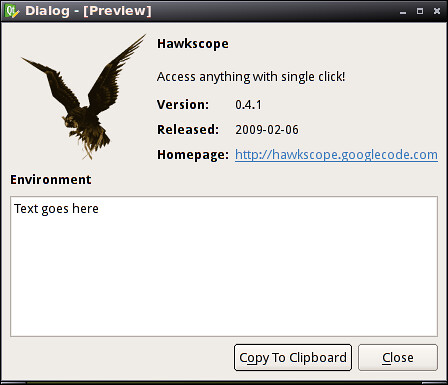
No, I didn't bother inserting text in the dialog so it loks the same ;-)
The "close" button closes the window, the URL opens in your system browser.
The text widget actually supports a subset of HTML, so there is a valid HTML document there, instead of just plain text.
Also, another thing is ... Designer's (or rather pyuic's) generated code is straightorward stuff.
Here's the code, which I think is roughly equivalent to his, only it's just 123 LOC, instead of 286 (his generated version) or 279 (his hand-made version). And I didn't delete the comments.
If I were doing this for real, all widgets would have descriptive names instead of PushButton1 and whatever.
Also, it's i18n-ready, unlike the Java versions, unless I missed something.
You can also get hawkscope.ui from this site to play with, it's done with Designer from Qt 4.4.
# -*- coding: utf-8 -*-
# Form implementation generated from reading ui file 'hawkscope.ui'
#
# Created: Fri Feb 13 22:39:47 2009
# by: PyQt4 UI code generator 4.4.4
#
# WARNING! All changes made in this file will be lost!
from PyQt4 import QtCore, QtGui
class Ui_Dialog(object):
def setupUi(self, Dialog):
Dialog.setObjectName("Dialog")
Dialog.resize(444, 357)
self.verticalLayout_2 = QtGui.QVBoxLayout(Dialog)
self.verticalLayout_2.setObjectName("verticalLayout_2")
self.horizontalLayout_2 = QtGui.QHBoxLayout()
self.horizontalLayout_2.setObjectName("horizontalLayout_2")
self.label_2 = QtGui.QLabel(Dialog)
self.label_2.setPixmap(QtGui.QPixmap("hawkscope.png"))
self.label_2.setAlignment(QtCore.Qt.AlignCenter)
self.label_2.setObjectName("label_2")
self.horizontalLayout_2.addWidget(self.label_2)
self.verticalLayout = QtGui.QVBoxLayout()
self.verticalLayout.setObjectName("verticalLayout")
self.label_3 = QtGui.QLabel(Dialog)
font = QtGui.QFont()
font.setWeight(75)
font.setBold(True)
self.label_3.setFont(font)
self.label_3.setObjectName("label_3")
self.verticalLayout.addWidget(self.label_3)
self.label_4 = QtGui.QLabel(Dialog)
self.label_4.setObjectName("label_4")
self.verticalLayout.addWidget(self.label_4)
self.gridLayout = QtGui.QGridLayout()
self.gridLayout.setObjectName("gridLayout")
self.label_5 = QtGui.QLabel(Dialog)
font = QtGui.QFont()
font.setWeight(75)
font.setBold(True)
self.label_5.setFont(font)
self.label_5.setObjectName("label_5")
self.gridLayout.addWidget(self.label_5, 0, 0, 1, 1)
self.label_10 = QtGui.QLabel(Dialog)
self.label_10.setObjectName("label_10")
self.gridLayout.addWidget(self.label_10, 0, 1, 1, 1)
self.label_9 = QtGui.QLabel(Dialog)
font = QtGui.QFont()
font.setWeight(75)
font.setBold(True)
self.label_9.setFont(font)
self.label_9.setObjectName("label_9")
self.gridLayout.addWidget(self.label_9, 1, 0, 1, 1)
self.label_8 = QtGui.QLabel(Dialog)
self.label_8.setObjectName("label_8")
self.gridLayout.addWidget(self.label_8, 1, 1, 1, 1)
self.label_7 = QtGui.QLabel(Dialog)
font = QtGui.QFont()
font.setWeight(75)
font.setBold(True)
self.label_7.setFont(font)
self.label_7.setObjectName("label_7")
self.gridLayout.addWidget(self.label_7, 2, 0, 1, 1)
self.label_6 = QtGui.QLabel(Dialog)
self.label_6.setOpenExternalLinks(True)
self.label_6.setObjectName("label_6")
self.gridLayout.addWidget(self.label_6, 2, 1, 1, 1)
self.verticalLayout.addLayout(self.gridLayout)
self.horizontalLayout_2.addLayout(self.verticalLayout)
self.verticalLayout_2.addLayout(self.horizontalLayout_2)
self.label = QtGui.QLabel(Dialog)
font = QtGui.QFont()
font.setWeight(75)
font.setBold(True)
self.label.setFont(font)
self.label.setObjectName("label")
self.verticalLayout_2.addWidget(self.label)
self.textBrowser = QtGui.QTextBrowser(Dialog)
self.textBrowser.setObjectName("textBrowser")
self.verticalLayout_2.addWidget(self.textBrowser)
self.horizontalLayout = QtGui.QHBoxLayout()
self.horizontalLayout.setObjectName("horizontalLayout")
spacerItem = QtGui.QSpacerItem(40, 20, QtGui.QSizePolicy.Expanding, QtGui.QSizePolicy.Minimum)
self.horizontalLayout.addItem(spacerItem)
self.pushButton = QtGui.QPushButton(Dialog)
self.pushButton.setObjectName("pushButton")
self.horizontalLayout.addWidget(self.pushButton)
self.pushButton_2 = QtGui.QPushButton(Dialog)
self.pushButton_2.setObjectName("pushButton_2")
self.horizontalLayout.addWidget(self.pushButton_2)
self.verticalLayout_2.addLayout(self.horizontalLayout)
self.retranslateUi(Dialog)
QtCore.QObject.connect(self.pushButton_2, QtCore.SIGNAL("clicked()"), Dialog.accept)
QtCore.QMetaObject.connectSlotsByName(Dialog)
def retranslateUi(self, Dialog):
Dialog.setWindowTitle(QtGui.QApplication.translate("Dialog", "Dialog", None, QtGui.QApplication.UnicodeUTF8))
self.label_3.setText(QtGui.QApplication.translate("Dialog", "Hawkscope", None, QtGui.QApplication.UnicodeUTF8))
self.label_4.setText(QtGui.QApplication.translate("Dialog", "Access anything with single click!", None, QtGui.QApplication.UnicodeUTF8))
self.label_5.setText(QtGui.QApplication.translate("Dialog", "Version:", None, QtGui.QApplication.UnicodeUTF8))
self.label_10.setText(QtGui.QApplication.translate("Dialog", "0.4.1", None, QtGui.QApplication.UnicodeUTF8))
self.label_9.setText(QtGui.QApplication.translate("Dialog", "Released:", None, QtGui.QApplication.UnicodeUTF8))
self.label_8.setText(QtGui.QApplication.translate("Dialog", "2009-02-06", None, QtGui.QApplication.UnicodeUTF8))
self.label_7.setText(QtGui.QApplication.translate("Dialog", "Homepage:", None, QtGui.QApplication.UnicodeUTF8))
self.label_6.setText(QtGui.QApplication.translate("Dialog", "<!DOCTYPE HTML PUBLIC \"-//W3C//DTD HTML 4.0//EN\" \"http://www.w3.org/TR/REC-html40/strict.dtd\">\n"
"<html><head><meta name=\"qrichtext\" content=\"1\" /><style type=\"text/css\">\n"
"p, li { white-space: pre-wrap; }\n"
"</style></head><body style=\" font-family:\'Droid Sans\'; font-size:8pt; font-weight:400; font-style:normal;\">\n"
"<p style=\" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;\"><a href=\"http://hawkscope.googlecode.com\"><span style=\" text-decoration: underline; color:#3c7dbe;\">http://hawkscope.googlecode.com</span></a></p></body></html>", None, QtGui.QApplication.UnicodeUTF8))
self.label.setText(QtGui.QApplication.translate("Dialog", "Environment", None, QtGui.QApplication.UnicodeUTF8))
self.textBrowser.setHtml(QtGui.QApplication.translate("Dialog", "<!DOCTYPE HTML PUBLIC \"-//W3C//DTD HTML 4.0//EN\" \"http://www.w3.org/TR/REC-html40/strict.dtd\">\n"
"<html><head><meta name=\"qrichtext\" content=\"1\" /><style type=\"text/css\">\n"
"p, li { white-space: pre-wrap; }\n"
"</style></head><body style=\" font-family:\'Droid Sans\'; font-size:8pt; font-weight:400; font-style:normal;\">\n"
"<p style=\" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;\">Text goes here</p>\n"
"<p style=\"-qt-paragraph-type:empty; margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;\"></p></body></html>", None, QtGui.QApplication.UnicodeUTF8))
self.pushButton.setText(QtGui.QApplication.translate("Dialog", "C&opy To Clipboard", None, QtGui.QApplication.UnicodeUTF8))
self.pushButton.setShortcut(QtGui.QApplication.translate("Dialog", "Alt+O", None, QtGui.QApplication.UnicodeUTF8))
self.pushButton_2.setText(QtGui.QApplication.translate("Dialog", "&Close", None, QtGui.QApplication.UnicodeUTF8))