THE DOPE on mars

|
|
|

|
Review:Not Doctorow's best book. |
Yes, it's yet another program I am working on. But hey, the last few I started are actually pretty functional already!
And... I am not doing this one alone, which should make it more fun.
It's an eBook (or just any book?) manager, that helps you keep your PDF/Mobi/FB2/whatever organized, and should eventually sync them to the device you want to use to read them.
What works now? See the video!
In case that makes no sense to you:
You can get books from FeedBooks. Those books will get downloaded, added to your database, tagged, the cover fetched, etc. etc.
You can import your current folder of books in bulk.
Aranduka will use google and other sources to try to guess (from the filename) what book that is and fill in the extra data about it.
You can "guess" the extra data.
By marking certain data (say, the title) as reliable, Aranduka will try to find some possible books that match then you can choose if it's right.
Of course you can also edit that data manually.
And that's about it. Planned features:
Way too many to list.
The goals are clear:
It should be beautiful (I know it isn't!)
It should be powerful (not yet!)
It should be better than the "competition"
If those three goals are not achieved, it's failure. It may be a fun failure, but it would still be a failure.
Sometimes, you see a piece of code and it just feels right. Here's an example I found when doing my "Import Antigravity" session for PyDay Buenos Aires: the progressbar module.
Here's an example that will teach you enough to use progressbar effectively:
Yes, that's it, you will get a nice ASCII progress bar that goes across the terminal, supports resizing and moves as you iterate from 0 to 79.
The progressbar module even lets you do fancier things like ETA or fie transfer speeds, all just as nicely.
Isn't that code just right? You want a progress bar for that loop? Wrap it and you have one! And of course since I am a PyQt programmer, how could I make PyQt have something as right as that?
Here'show the output looks like:
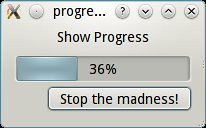
You can do this with every toolkit, and you probably should!. It has one extra feature: you can interrupt the iteration. Here's the (short) code:
# -*- coding: utf-8 -*- import sys, time from PyQt4 import QtCore, QtGui def progress(data, *args): it=iter(data) widget = QtGui.QProgressDialog(*args+(0,it.__length_hint__())) c=0 for v in it: QtCore.QCoreApplication.instance().processEvents() if widget.wasCanceled(): raise StopIteration c+=1 widget.setValue(c) yield(v) if __name__ == "__main__": app = QtGui.QApplication(sys.argv) # Do something slow for x in progress(xrange(50),"Show Progress", "Stop the madness!"): time.sleep(.2)
Have fun!

|
Review:A real page turner. Taking advantage of it being CC, I think I may attempt translating it to spanish (argentinian flavour) |