Urssus: July 29th - Moo till it's done
I may have gotten a bit carried away with mootools: Combined view now has an accordion-like thing google-reader style.
Not too pretty, but pretty's not my thing.
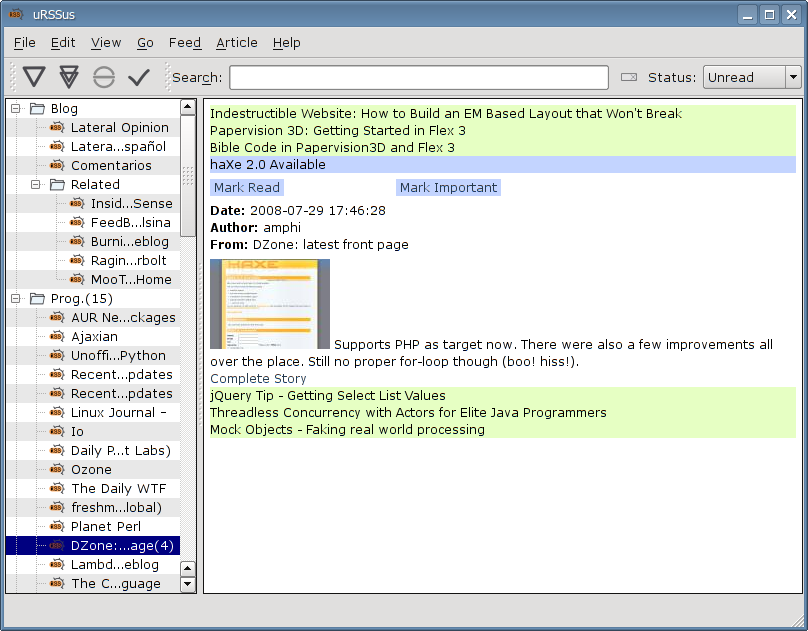
Urssus: July 29th - An original feature, at last (with screenshot)
Tired of chasing after other program's features, I took a detour on the original feature road: the combined view is now much nicer than Akregator's.
Why? Because you can use it and still flag individual articles as read/unread/important.
Using a tiny bit of mootools and some rudimentary javascript, plus a wee Tenjin template effort...
And yes, the "buttons" appear and disappear as needed, and update the GUI just like they should.
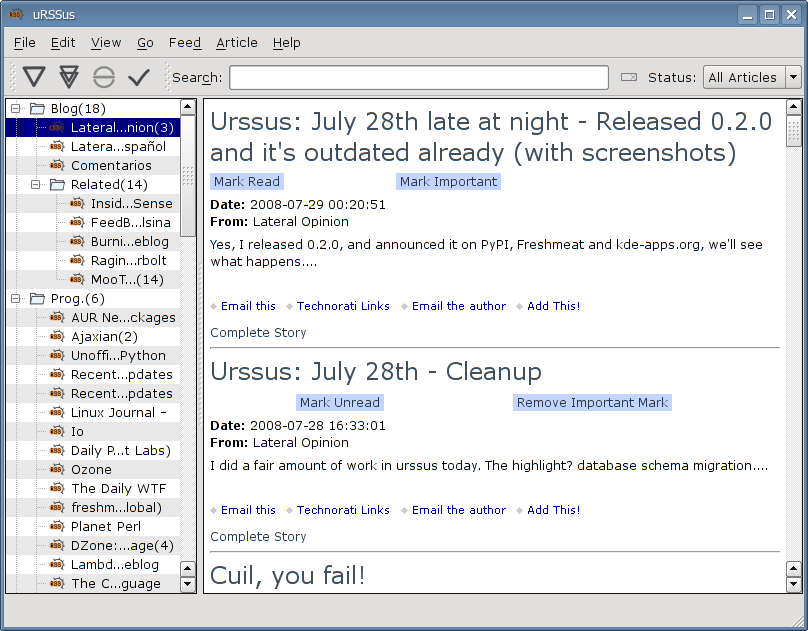
Urssus: July 28th late at night - Released 0.2.0 and it's outdated already (with screenshots)
Yes, I released 0.2.0, and announced it on PyPI, Freshmeat and kde-apps.org, we'll see what happens.
But why is it outdated? Because I am doing nicer UI work, already.
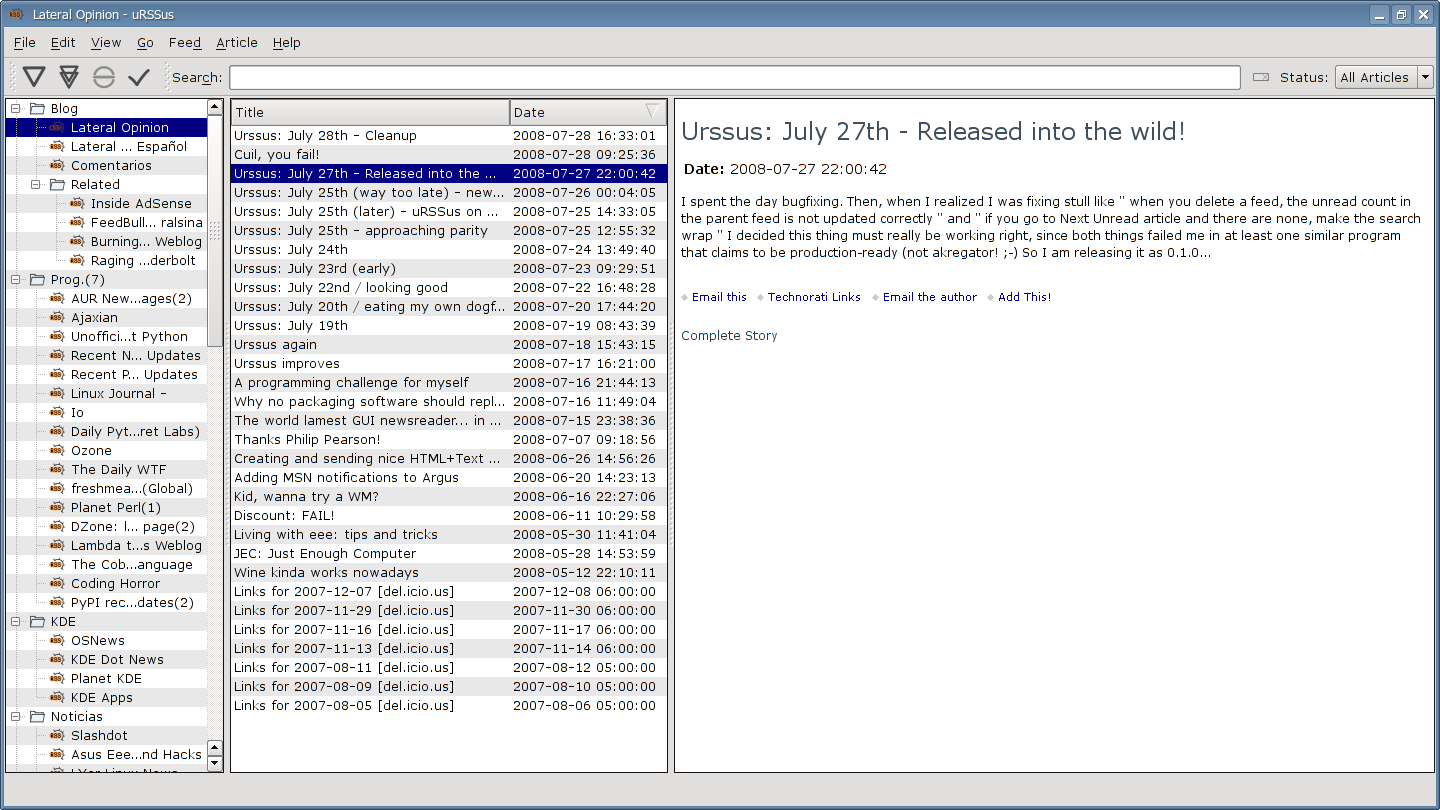
The search widget is now a bottom-locked toolbar, which is much cleaner.
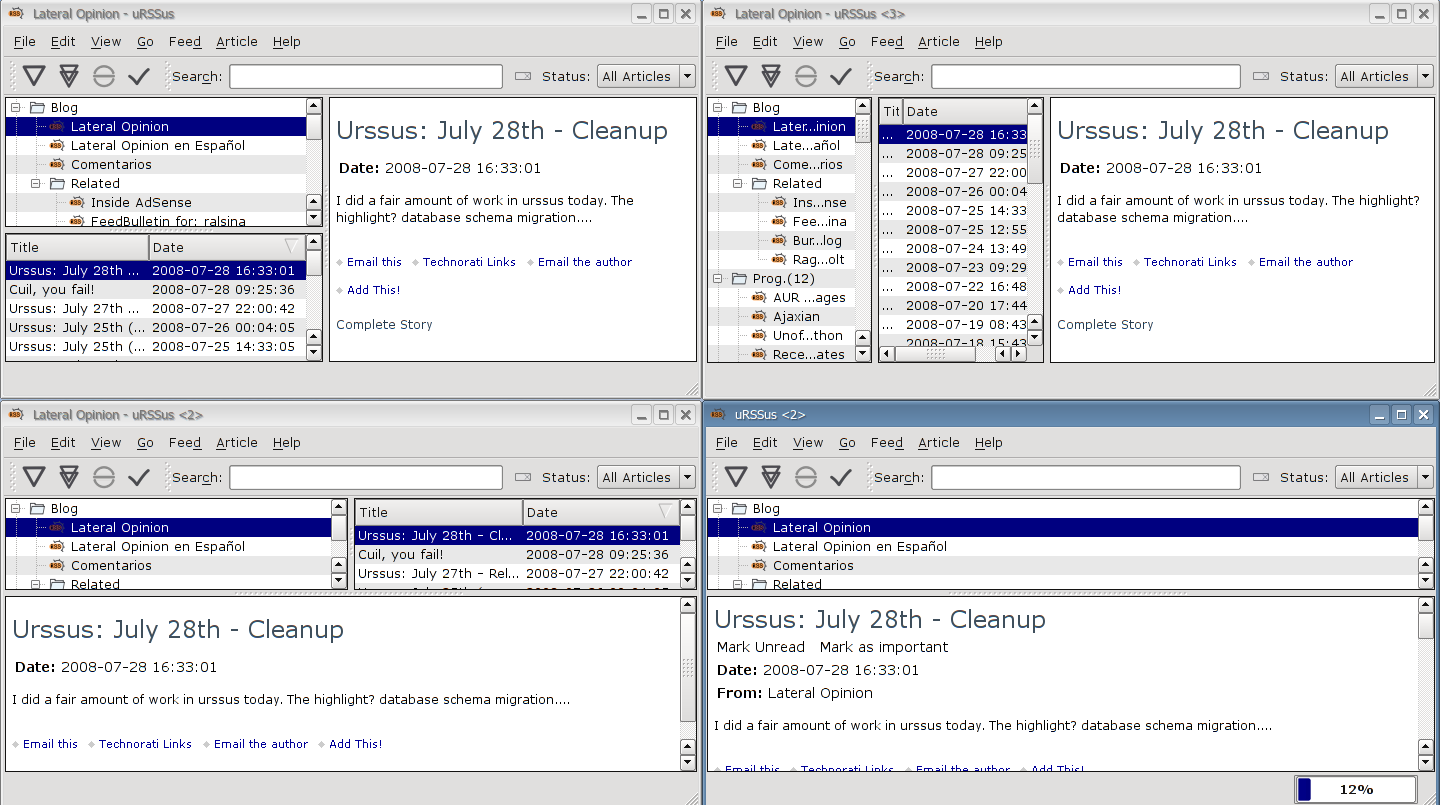
There are now 3 window layouts (normal, widescreen and combined) and each has a "long feed list" and a "short feed list" variant.
Here is widescreen-long:
And here are widescreen-short, widescreen-long, normal-short, and combined-short, all scrunched in a single screen (yes, you can run multiple urssus (urssuses? urssi?):
Urssus: July 28th - Cleanup
I did a fair amount of work in urssus today. The highlight? database schema migration.
Here is the (not really) full list:
Fixes on the installer
Fix in importOPML
Raise the window when you click on the systray popup
Fixed several issues after feed deletion
Fixed several issues with feeds not updating the UI's unread count
Fixed the look of buttons on searchWidget and filterWidget
And several more...
And the big one:
Implemented database schema versioning using sqlalchemy-migrate.
What does that mean? That I can change the database and the user will not notice anything.
On startup, uRSSus checks if you are using the correct schema, and updates your database accordingly.
For example, I can now implement manual feed sorting just adding a "position" column to the Feed class. If I had not implemented this, that would require a much greater hack.
Now? I just do it, write an upgrade/downgrade script, and that's all. Migrate is really a very cool tool, and shows the strength of using SQLAlchemy (not so much that of using Elixir, because they get along grudgingly ;-)
Current LOC count: 1491
Current status: still fun! (and educational!)