Rebelling against insanity: Wicd requires half of GNOME
UPDATE: you can get this program now at google code
I have been using my eee for a while already with a sort of Kubuntu in it.
However, my favourite wireless/wired network management app is wicd, which is a Python/GTK application. Or was, since version 1.4.1 requires python-gnome2-extras.
Which depends on ....
libart-2.0-2 (>= 2.3.18), libaspell15 (>= 0.60), libatk1.0-0 (>= 1.13.2), libbonobo2-0 (>= 2.15.0), libbonoboui2-0 (>= 2.15.1), libc6 (>= 2.6-1), libcairo2 (>= 1.4.0), libfontconfig1 (>= 2.4.0), libfreetype6 (>= 2.3.5), libgconf2-4 (>= 2.13.5), libgda3-3, libgdl-1-0, libgdl-gnome-1-0, libgksu1.2-1 (>= 1.3.3), libgksu2-0 (>= 1.9.6), libgksuui1.0-1, libglade2-0 (>= 1:2.6.1), libglib2.0-0 (>= 2.14.0), libgnome-keyring0 (>= 2.19.6), libgnome2-0 (>= 2.17.3), libgnomecanvas2-0 (>= 2.11.1), libgnomeui-0 (>= 2.19.1), libgnomevfs2-0 (>= 1:2.17.90), libgtk2.0-0 (>= 2.12.0), libgtkspell0 (>= 2.0.2), libice6 (>= 1:1.0.0), libnspr4-0d (>= 1.8.0.10), liborbit2 (>= 1:2.14.8), libpango1.0-0 (>= 1.18.2), libpng12-0 (>= 1.2.13-4), libpopt0 (>= 1.10), libsm6, libstartup-notification0 (>= 0.8-1), libx11-6, libxcomposite1 (>=1:0.3-1), libxcursor1 (>> 1.1.2), libxdamage1 (>= 1:1.1), libxext6, libxfixes3 (>= 1:4.0.1), libxi6, libxinerama1, libxml2 (>= 2.6.29), libxrandr2 (>= 2:1.2.0), libxrender1, zlib1g (>= 1:1.2.3.3.dfsg-1), python-support (>= 0.3.4), python (<< 2.6), python (>= 2.4), python-gtk2, python-pyorbit, python-gnome2-desktop
In short: a 87MB download. That can't be good. In fact, there are almost no changes from 1.3.1 which didn't require all that! Except for one change that makes all the difference on a eee PC: vertical resizing to under 400px. :-(
So, because I am who I am, I did this:
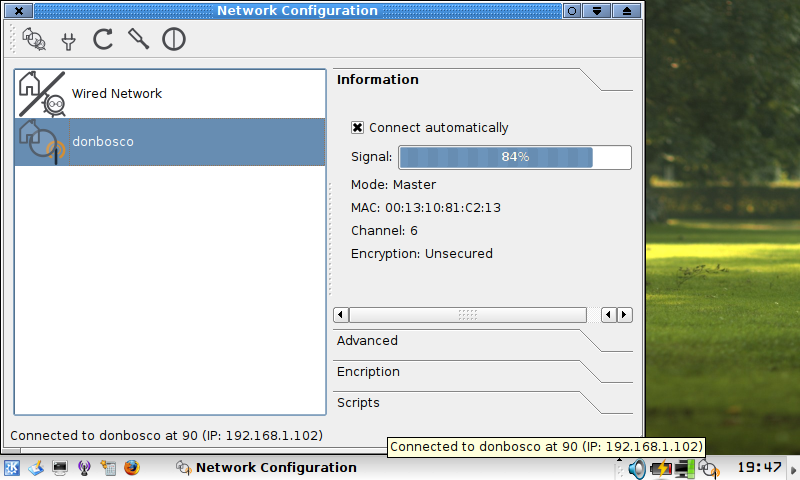
It's a replacement for wicd's gui.py and tray.py. Only needs PyQt4 which I already had and depends on:
libc6 (>= 2.6-1), libgcc1 (>= 1:4.2.1), libqt4-core (>= 4.3.2), libqt4-gui (>= 4.3.2), libstdc++6 (>= 4.2.1), python-central (>= 0.5.8), python (<< 2.6), python (>= 2.4), python-sip4 (>= 4.7), python-sip4 (<< 4.8)
See a difference there?
Took me about 3 hours to hack together, and works (except for wired config, the prefs dialog, static IP and scripts) but the hard work is done.
If anyone wants a copy, just ask. I expect KUbuntu could use something like it?