Son of bartleblog XI: the highlight of the syntax
I had a few minutes waiting for yum to do its thing and added a couple of easy features:
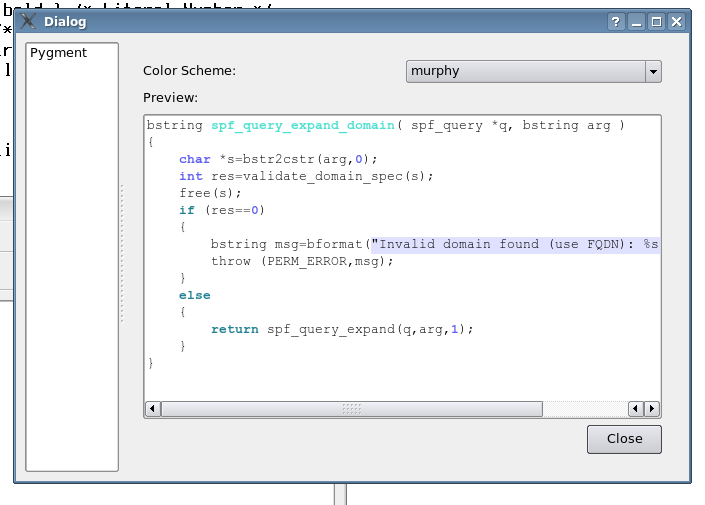
The SilverCity-based code-block syntax highlighting directive was replaced with a version using Pygment which supports more languages and is (I think) nicer looking... and comes with several styles, as you can see above in the configuration dialog.
Other than that, I added support in the backend to:
Regenerate HTML from RST everywhere
Do the same only on items marked "dirty"
A model thingie that shows if there are posts or stories with RST errors
Some GUI love
I need to make the config dialog support more than one gadget at the same time, though ;-)