In January, I suggested it would be trivial to write a preprocessor that would accept a version of python which delimited blocks with braces instead of indentation.
Ok, almost, I suggested #{ and #} as delimiters.
Well, I had a few minutes free today, and here it is, a functional BPython->Python compiler, so to speak.
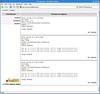
Here's the kind of imput it takes (notice how it's not indented at all:
def factorial(n):
#{
if n==1:
#{
return 1
#}
else:
#{
return n*factorial(n-1)
#}
#}
for x in range(1,10):
#{
print x,"!=",factorial(x)
#}
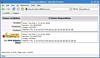
And it produces this (I am not happy with the indenting of the comments, but who cares):
def factorial(n):
#{
if n==1:
#{
return 1
#}
else:
#{
return n*factorial(n-1)
#}
#}
for x in range(1,10):
#{
print x,"!=",factorial(x)
#}
As you can see, this is both a legal Python and a legal BPython program ;-)
It has some problems, like not working when you use a line like this:
#{ x=1
But hey, it is python with braces.
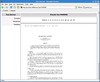
Here's the code. I predicted 30 lines. It's 34. And it's 99% a ripoff of Ka Ping Yee's regurgitate.py which you can find all around the web.
#!/usr/bin/env python
import tokenize, sys
program = []
lastrow, lastcol = 1, 0
lastline = ''
indlevel=0
def rebuild(type, token, (startrow, startcol), (endrow, endcol), line):
global lastrow, lastcol, lastline, program,indlevel
if type==52 and token.startswith ("#{"):
type=5
indlevel+=1
if type==52 and token.startswith ("#}"):
type=6
indlevel-=1
line=" "*indlevel+line.lstrip()
startcol+=indlevel*2
endcol+=indlevel*2
# Deal with the bits between tokens.
if lastrow == startrow == endrow: # ordinary token
program.append(line[lastcol:startcol])
elif lastrow != startrow: # backslash continuation
program.append(lastline[lastcol:] + line[:startcol])
elif startrow != endrow: # multi-line string
program.append(lastline[lastcol:startcol])
# Append the token itself.
program.append(token)
# Save some information for the next time around.
if token and token[-1] == '\n':
lastrow, lastcol = endrow+1, 0 # start on next line
else:
lastrow, lastcol = endrow, endcol # remember last position
lastline = line # remember last line
tokenize.tokenize(sys.stdin.readline, rebuild)
for piece in program: sys.stdout.write(piece)
So, all of you who dislike python because of the lack of braces and the significant whitespace:
BPython has no significant whitespace, and braces are mandatory.
Enjoy coding!