Again, spanish only because it's a video... in spanish.
Resulta que me olvidé que sí habían grabado mi charla de docutils y compañia. Gracias a Germán por hacerme acordar y mostrarme adonde estaba!
rst2pdf is a tool to convert restructured text (a light, cool markup language) to PDF using reportlab instead of LaTeX.
It has been used for many things, from books, to magazines, to brochures, to manuals, to websites and has lots of features:
Font embedding (TTF or Type1 fonts)
Cascading Stylesheets
Extremely flexible plugin architecture (you can do things
like render the headings from arbitrary SVG files!)
Sphinx integration.
Configurable page layouts
Custom cover pages via templates
And much, much more...
The biggest change in 0.16 is surely the improved support for Sphinx 1.0.x so if you are using Sphinx, you really want this version.
Also, it has a ton of bugfixes, and a few minor but useful new features.
Here's the whole changelog if you don't believe me:
Fixed Issue 343: Plugged memory leak in the RSON parser.
Fix for Issue 287: there is still a corner case if you have two sections
with the same title, at the same level, in the same page, in different files
where the links will break.
Fixed Issue 367: german-localized dates are MM. DD. YYYY so when used in sphinx's
template cover they appeared weird, like a list item. Fixed with a minor workaround in
the template.
Fixed Issue 366: links to "#" make no sense on a PDF file
Made definitions from definition lists more stylable.
Moved definition lists to SplitTables, so you can have very long
definitions.
Fixed Issue 318: Implemented Domain specific indexes for Sphinx 1.0.x
Fixed Index links when using Sphinx/pdfbuilder.
Fixed Issue 360: Set literal.wordWrap to None by default so it doesn't inherit
wordWrap CJK when you use the otherwise correct japanese settings. In any case,
literal blocks are not supposed to wrap at all.
Switched pdfbuilder to use SplitTables by default (it made no sense not to do it)
Fixed Issue 365: some TTF fonts don't validate but they work anyway.
Set a valid default baseurl for Sphinx (makes it much faster!)
New feature: --use-numbered-links to show section numbers in links to sections, like "See section 2.3 Termination"
Added stylesheets for landscape paper sizes (i.e: a4-landscape.style)
Fixed Issue 364: Some options not respected when passed in per-doc options
in sphinx.
Fixed Issue 361: multiple linebreaks in line blocks were collapsed.
Fixed Issue 363: strange characters in some cases in math directive.
Fixed Issue 362: Smarter auto-enclosing of equations in $...$
Fixed Issue 358: --real--footnotes defaults to False, but help text indicates default is True
Fixed Issue 359: Wrong --fit-background-mode help string
Fixed Issue 356: missing cells if a cell spawns rows and columns.
Fixed Issue 349: Work correctly with languages that are available in form aa_bb and not aa (example: zh_cn)
Fixed Issue 345: give file/line info when there is an error in a raw PDF directive.
Fixed Issue 336: JPEG images should work even without PIL (but give a warning because
sizes will probably be wrong)
Fixed Issue 351: footnote/citation references were generated incorrectly, which
caused problems if there was a citation with the same text as a heading.
Fixed Issue 353: better handling of graphviz, so that it works without vectorpdf
but gives a warning about it.
Fixed Issue 354: make todo_node from sphinx customizable.
Fixed bug where nested lists broke page layout if the page was small.
Smarter --inline-links option
New extension: fancytitles, see //ralsina.me/weblog/posts/BB906.html
New feature: tab-width option in code-block directive (defaults to 8).
Fixed Issue 340: endnotes/footnotes were not styled.
Fixed Issue 339: class names using _ were not usable.
Fixed Issue 335: ugly crash when using images in some
specific places (looks like a reportlab bug)
Fixed Issue 329: make the figure alignment/class attributes
work more like LaTeX than HTML.
Fixed Issue 328: list item styles were being ignored.
Fixed Issue 186: new --use-floating-images makes images with
:align: set work like in HTML, with the next flowable flowing
beside it.
Fixed Issue 307: header/footer from stylesheet now supports inline
rest markup and substitutions defined in the main document.
New pdf_toc_depth option for Sphinx/pdfbuilder
New pdf_use_toc option for Sphinx/pdfbuilder
Fixed Issue 308: compatibility with reportlab from SVN
Fixed Issue 323: errors in the config.sample made it work weird.
Fixed Issue 322: Image substitutions didn't work in document title.
Implemented Issue 321: underline and strikethrough available
in stylesheet.
Fixed Issue 317: Ugly error message when file does not exist
That a plugin architecture for a complex app is a good idea is one of
those things that most people kinda agree on. One thing we don't
quite agree is how the heck are we going to make out app modular?
One way to do it (if you are coding python) is using Yapsy.
Yapsy is awesome. Also, yapsy is a bit underdocumented. Let's see
if this post fixes that a bit and leaves just the awesome.
Update: I had not seen the new Yapsy docs, released a few days ago. They are much better than what was there before :-)
Here's the general idea behind yapsy:
You create a Plugin Manager that can find and load plugins from a list
of places (for example, from ["/usr/share/appname/plugins",
"~/.appname/plugins"]).
A plugin category is a class.
There is a mapping between category names and category classes.
A plugin is a module and a metadata file. The module defines a
class that inherits from a category class, and belongs to that
category.
The metadata file has stuff like the plugin's name, description,
URL, version, etc.
One of the great things about Yapsy is that it doesn't specify too much.
A plugin will be just a python object, you can put whatever you want there,
or you can narrow it down by specifying the category class.
In fact, the way I have been doing the category classes is:
Start with an empty class
Implement two plugins of that category
If there is a chunk that's much alike in both, move it into
the category class.
But trust me, this will all be clearer with an example :-)
I will be doing it with a graphical PyQt app, but Yapsy works just as
well for headless of CLI apps.
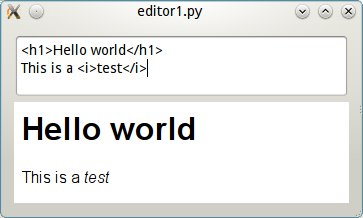
Let's start with a simple app: an HTML editor with a preview widget.
A simple editor with preview
Here's the code for the app, which is really simple (it doesn't save or do
anything, really, it's just an example):
But this application has an obvious limit: you have to type HTML in it. Why not
type python code in it and have it convert to HTML for display? Or Wiki markup,
or restructured text?
You could, in principle, just implement all those modes, but then you are assuming
the responsability of supporting every thing-that-can-be-turned-into-HTML. Your
app would be a monolith. That's where yapsy enters the scene.
So, let's create a plugin category, called "Formatter" which takes plain
text and returns HTML. Then we add stuff in the UI so the user can choose what
formatter he wants, and implement two of those.
Here's our plugin category class:
Of course what good is a plugin architecture without any plugins for it? So,
let's create two plugins.
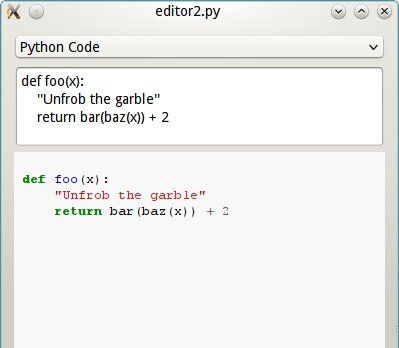
First: a plugin that takes python code and returns HTML, thanks to pygments.
See how it goes into a plugins folder? Later on we will tell yapsy to search
there for plugins.
To be recognized as a plugin, it needs a metadata file, too:
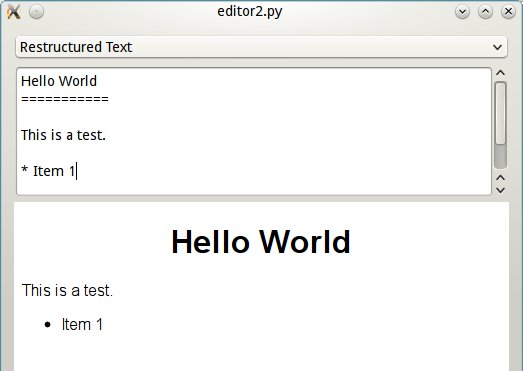
And really, that's all there is to making a plugin. Here's another one
for comparison, which uses docutils to format reStructured Text:
And here they are in action:
reSt mode
Python mode
Of course using categories you can do things like a "Tools" category, where the
plugins get added to a Tools menu, too.
And here's the application code:
In short: this is easy to do, and it leads to fixing your application's internal
structure, so it helps you write better code.
One of my favourite things about Aranduka as a project is that it's an endless source of small, limited side projects.
For example, Aranduka is now close to being able to sync my book collection to my phone. But... what if what I want to read on the train is not a book but, say, a blog?
Well, blogs provide their content via a feed. And A feed is a collection of HTML pieces glued into a structure plus some data like author and such.
And there's a great module for parsing them, called feedparser. And I have written not one, not two, not three, but four RSS aggregators in the past.
So, how about converting the feed into something my phone can handle? [#] Would it be hard to do?
Well... not really hard. It's mostly a matter of taking a small, sample ePub document (created by Calibre) writing a few templates, feeding it the data from feedparser and zipping it up.
For example, this is this blog, as an ePub and here's FBReader reading it:
It's not really interesting code, and requires templite feedparser and who knows what else.
The produced ePub doesn't validate, and it probably never will, because it has chunks of the original feed in it, so standard compliance doesn't depend on rss2epub.
Also, you get no images. That would imply parsing and fixing all img elements, I suppose, and I am not going to do it right now.
[#] I first saw this feature in plucker a long time ago, and I know Calibre has it too.
Yes, it's yet another program I am working on. But hey, the last few I started are actually pretty functional already!
And... I am not doing this one alone, which should make it more fun.
It's an eBook (or just any book?) manager, that helps you keep your PDF/Mobi/FB2/whatever organized, and should eventually sync them to the device you want to use to read them.
You can get books from FeedBooks. Those books will get
downloaded, added to your database, tagged, the cover
fetched, etc. etc.
You can import your current folder of books in bulk.
Aranduka will use google and other sources to try to
guess (from the filename) what book that is and fill
in the extra data about it.
You can "guess" the extra data.
By marking certain data (say, the title) as reliable,
Aranduka will try to find some possible books that match
then you can choose if it's right.
Of course you can also edit that data manually.
And that's about it. Planned features:
Way too many to list.
The goals are clear:
It should be beautiful (I know it isn't!)
It should be powerful (not yet!)
It should be better than the "competition"
If those three goals are not achieved, it's failure. It may be a fun failure, but it would still be a failure.